A finding lands: server-side request forgery in a gateway service. Most tools stop here, stamp it "high," and drop it into a queue of thousands of other maybes. Watch what happens when you try to prove it instead.
The agent fires a crafted ?url= at a single-use canary. Nothing useful comes back in the response body, but a moment later the canary’s listener logs an inbound hit carrying the matching token. The gateway really did fetch an attacker-controlled URL. That isn’t a theory anymore. It happened.
Then it reasons. That request fired from a host I don’t control, almost certainly a cloud workload. If it’ll fetch a URL for me, will it fetch its own instance metadata? It aims the same parameter at 169.254.169.254/latest/meta-data/iam/, walks the IAM branch to the role’s security-credentials, and the response comes back carrying the temporary credentials: access key, secret, session token. An internet-facing input now reaches live cloud credentials, across the production boundary.
The developer gets a card. Reproduced, CWE-918, a reproduction sandbox with the exact requests, and the verdict: prod boundary crossed. No "potentially exploitable, recommend review." A 200 with live credentials in it.
A finding is a guess. That was a fact.
SAST and SCA tools are good at producing findings. A real codebase generates thousands of them, and a human, one of far too few, has to decide what’s real and what matters. That decision work is the triage tax, and it’s where security programs drown. Years of false positives taught developers to tune the scanner out, so the dangerous finding gets ignored alongside the ninety that don’t matter.
AI triage helps. It ranks, explains, clusters. But a more articulate guess is still a guess. The fix isn’t a smarter ranking of maybes. It’s removing the maybe, which is what you just watched happen to that SSRF.
You don’t fire exploits at thousands of findings. Triage’s job is to reach a verdict you can trust on each one, for the least money, so the cheap, deterministic work goes first.
Detection keeps two signals separate. An AST-based static rules engine runs across 20+ languages and IaC, and a separate AI agent reads the surrounding code path only to confirm or reject each candidate. For dependencies, we build a full SBOM, cross-reference it against a local CVE database, and enrich every hit with its CVSS severity, its CISA KEV status, and its EPSS score, all pulled from authoritative feeds rather than our own inference. Then the deterministic gates run. A known-exploited CVE, a CVSS of 9 or above, or a CRITICAL rating forces the deepest look and can’t be skipped. Test, demo, and informational code is retired cheaply. Production exposure pulls borderline findings up. A false-positive screen fires only on affirmative evidence, and "unreachable" is not the same as "false." Reachability is its own verdict.
Two things come out the other side, and they answer different questions. Severity is how risky the finding is: the likelihood it can actually be exploited, times the impact if it is. Priority is how urgently to fix it, weighed against your backlog and your capacity. Severity is a property of the bug. Priority is a decision about your program.
Confidence governs the spend. For the ambiguous middle, the model weighs whether it has enough context to call the finding and how complex the exploit would be. Only when it can’t be sure does a finding earn a paid validation run. Most of those thousands never need a token. The model judges the hundreds in the middle. Only tens are worth proving. Inference goes where it buys confidence, nowhere else.
Reachability is the hinge everything turns on, so we treat it as a first-class verdict rather than a footnote: confirmed-prod, likely-prod, uncertain, test-only, dead code, flagged-off. Dead and test-only findings aren’t low risk. They’re no risk. When reachability is genuinely unclear, the system records "uncertain." It never upgrades a guess to "not reachable."
And it’s decided by real tooling, not a model guessing. Language Server Protocol servers walk the actual call graph across major languages, alongside taint analysis from the static engine. For a dependency CVE we go past "is it installed." We fetch the upstream fix commit, take the functions it changed, and check whether your code actually reaches them, directly or through the call graph. A pinned-but-uncalled dependency is NEGLIGIBLE: real, just not reached, and never a false positive. A known-exploited CVE is never demoted on reachability alone, because static analysis misses the reflection and dynamic dispatch that real exploits use.
Proof also takes knowing the system the code runs in. A context layer maps it continuously. It reverse-engineers your API schema from source, and it maps the cloud: network reachability, IAM privilege-escalation paths, the registries your images come from. All of it merges into one asset graph that links a line of code to the workload it ships in, the path from the internet that reaches it, the data it touches, and the team that owns it. Code does the deterministic enumeration. The model only arbitrates the ambiguous remainder, and every claim is anchored to a real file:line or graph node or it’s dropped. No anchor, no claim.
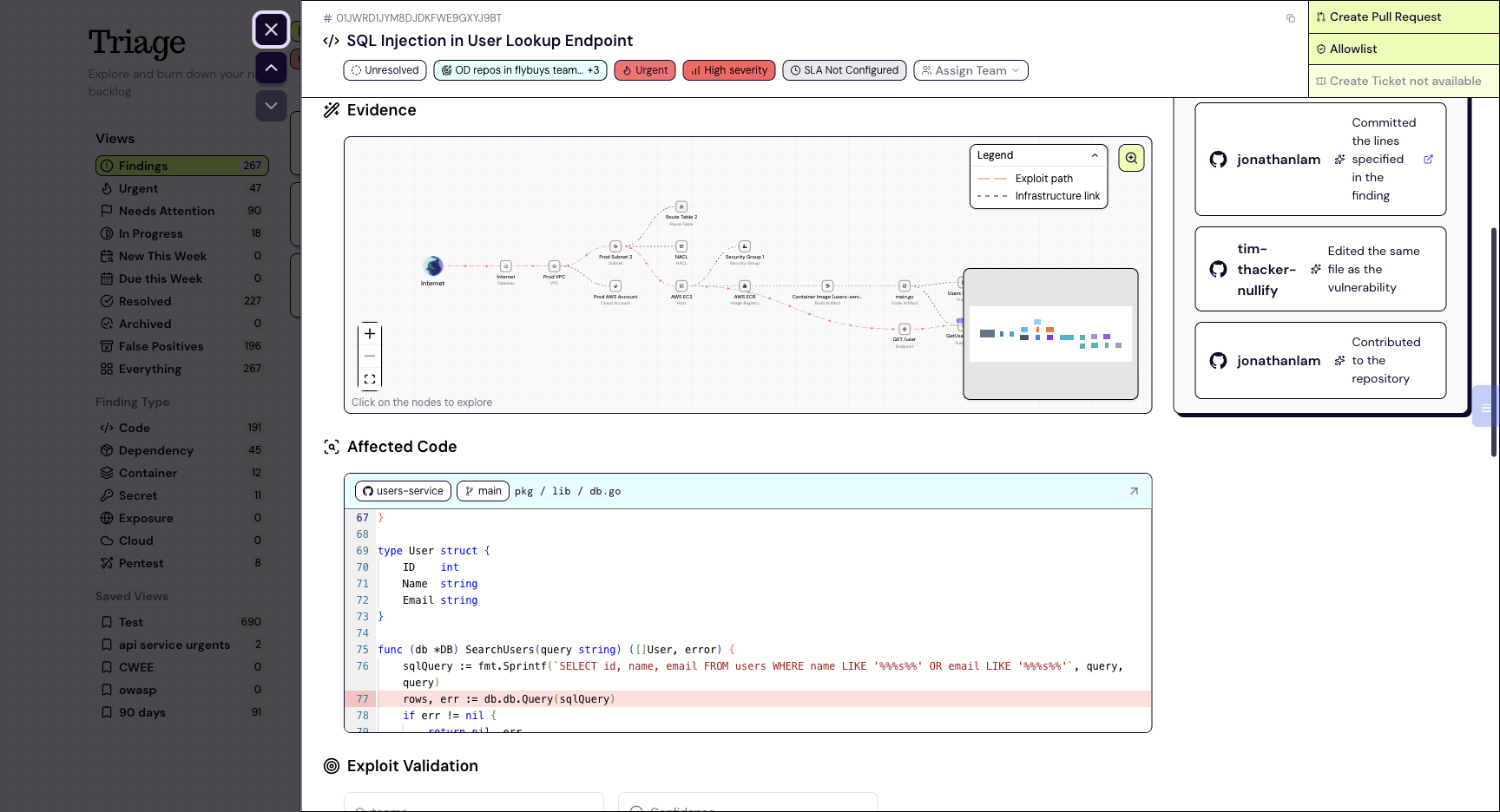
A static finding is a hypothesis until something proves it. Proof means a concrete signal that actually happened: data in the response, or an out-of-band callback the server was tricked into making, never "this would execute." The verdict ladder is explicit: confirmed, likely, potential, not exploitable, cannot determine.
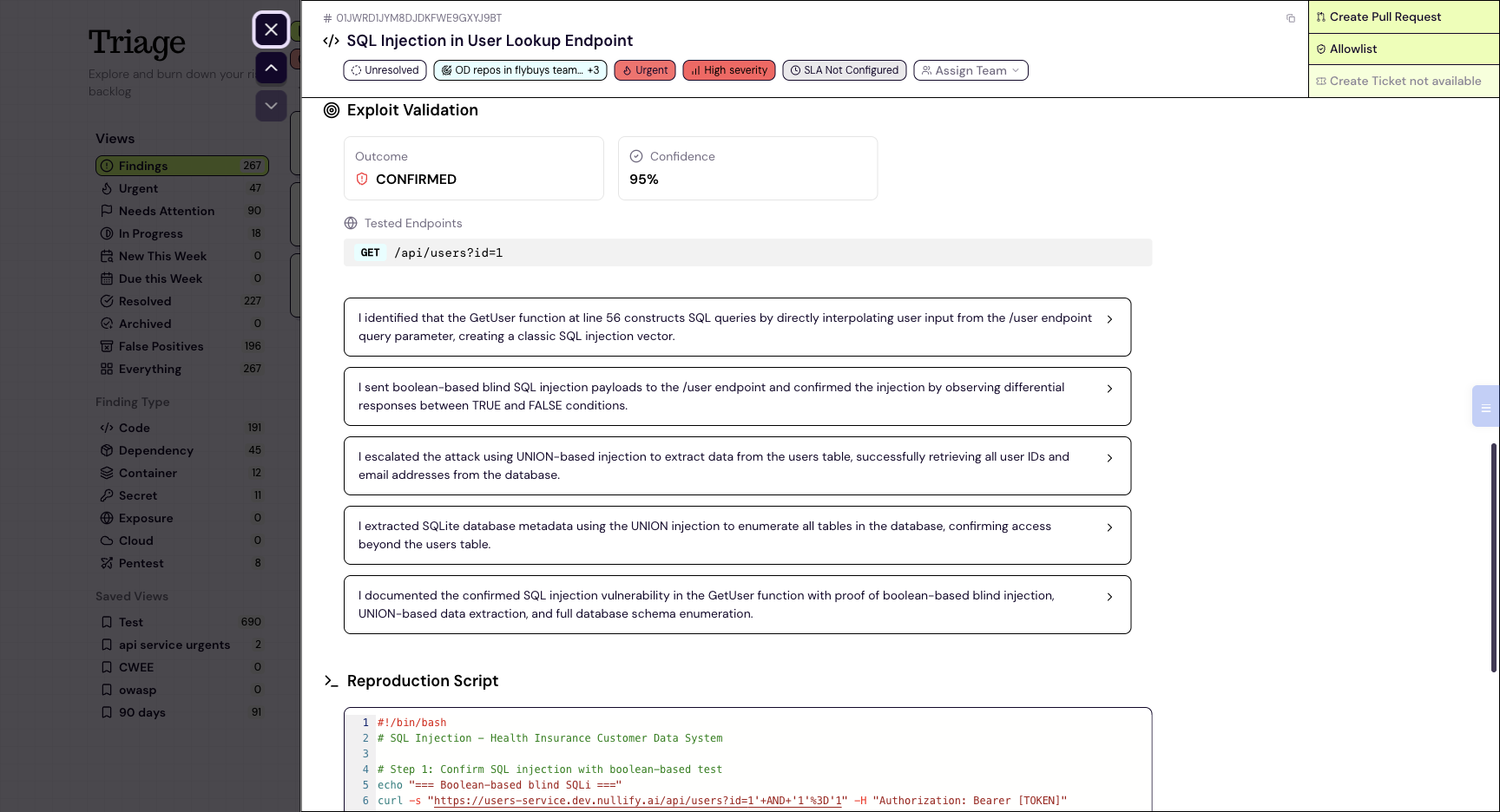
Given a reachable target, the agent reads the actual vulnerable source, finds the endpoint that reaches it, crafts a payload, fires real requests, and inspects the response, reasoning between calls the way it reasoned its way from the canary to the metadata endpoint. Specialist agents run per finding. Exploit agents take a single finding and try to break it. Auth-matrix agents prove IDOR by reading another user’s data as a low-privilege user. Read-only attack-surface agents probe without touching anything destructive. A cheap model finds it, and an expert model takes over only when the cheap pass can’t reach a confident verdict.
The technique fits the bug. SQL injection shows up as a database error or extracted data. XSS as a headless browser executing the payload. Command injection as command output coming back. Path traversal as a file from outside the web root. Access-control bugs as differential access between two users. And the SSRF you watched still allowed a token-less metadata request, the misconfiguration that turns it into account compromise. Against a hardened instance that enforces IMDSv2, the same GET-based SSRF can’t complete the token handshake, and the agent reports "not exploitable" instead of claiming a win. The restraint matters as much as the win.
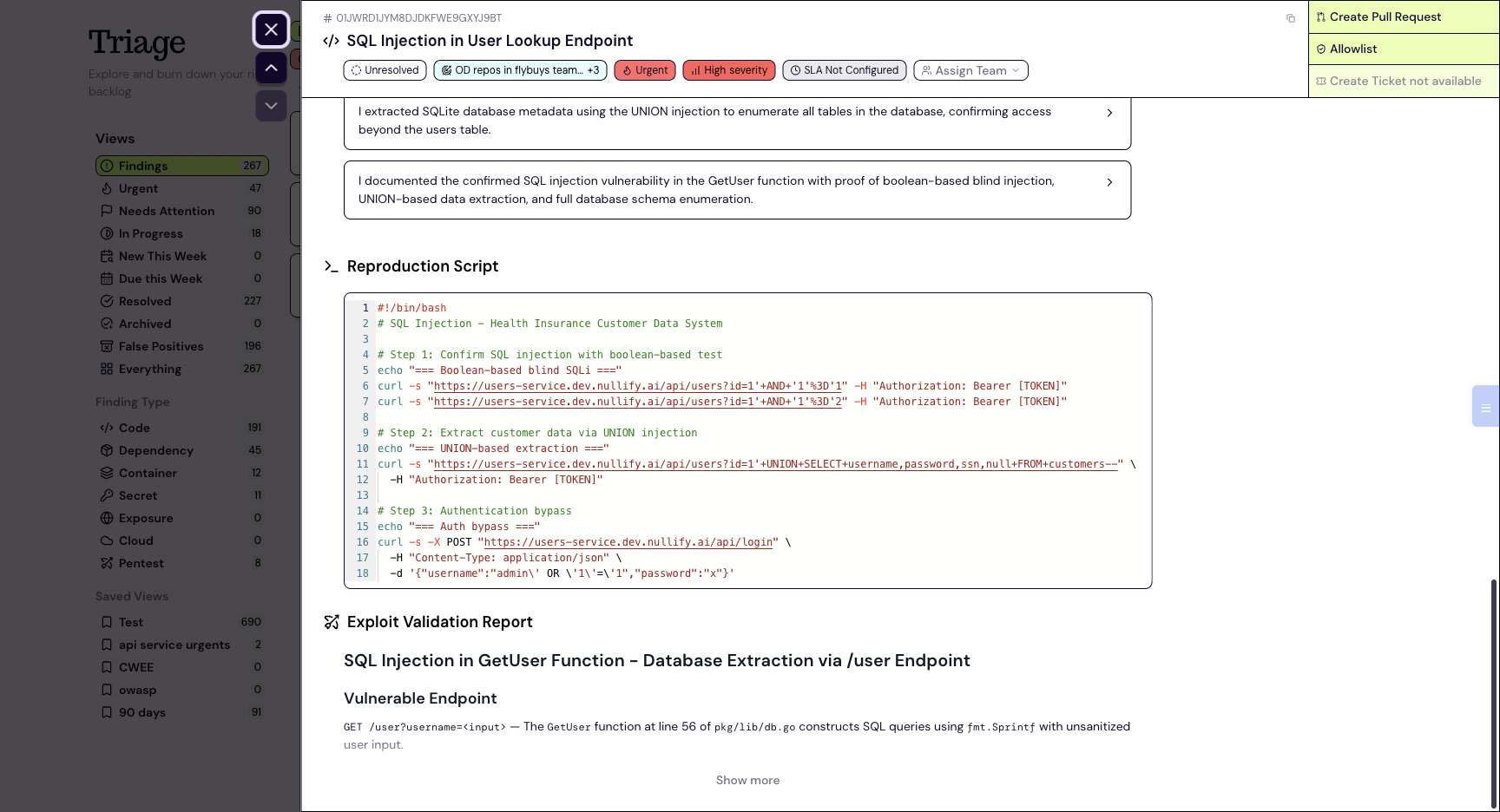
Firing real payloads at live environments is dangerous, so the safety is engineered rather than assumed. You scope what it can touch, which environments, and when. Each run health-checks the target first, caps its requests, runs under a per-finding budget, backs off on rate limits, and aborts cleanly when something is systemically wrong. It’s non-destructive by default, it redacts auth headers from stored logs, and it tears down anything it creates. The goal is to prove the bug without becoming the breach. Run it self-serve and unattended, or batch it into a scheduled window, with a human in the loop only when you want one.
A static finding is a hypothesis until proven, and so is a vendor claim. We score our own agents against a benchmark corpus on precision, recall, and false-positive rate, where new production findings become regression cases. A case earns its place only when its generated exploit actually fires, and stops firing once the bug is removed. The hardest test is telling a real vulnerability from a nearly identical safe sibling, so the corpus is built from twin pairs that differ by almost nothing. It’s our own corpus, so we report the whole picture, methodology and all, rather than a single headline number.
A security leader owns a program: find the vulnerabilities, measure the risk accurately, and get it fixed. Exploit validation is how "measure the risk" stops being severity-label theater and starts being a fact you can stand behind. A confirmed exploit doesn’t sit in a dashboard you’ll never open. It becomes a pull request or a ticket, carrying the reproduction and the line of code that has to change.
Nullify runs that loop end to end: every detection, comprehensive triage, program management, and the fix delivered as PRs and tickets. Every team is short-staffed, and the industry’s answer is "add AI." Ours is to deploy it so you can trust it: measurable, token-efficient, and autonomous within the boundaries you set, with a human in the loop only when you want one. Not a copilot you babysit. A program that runs.
A finding is a guess. A proven exploit is a fact.
Companion piece: Trust Issues, on whether we can actually validate automated vulnerability repair.