Trust Issues: Can We Actually Validate Automated Vulnerability Repair?

The need for security remediation grows with everything we move into software. A larger share of our lives runs on code, the attack surface grows with it, and the cost of leaving a vulnerability in production keeps climbing. AI coding assistants have poured fuel on the fire: developers now ship far more code, far faster, and a meaningful share of what these models write still arrives with vulnerabilities. More code at a stubborn defect rate adds up to more vulnerabilities reaching production, not fewer. The same technology now sits on both sides of the problem: automated vulnerability repair (AVR), the practice of remediating vulnerabilities with little human intervention, has advanced quickly on the back of LLM-driven systems.
Any system whose output you cannot fully predict raises the same question: how do we know the remediation it produced is any good? Three things have to hold.
- Functionality is preserved. Legitimate inputs still produce correct results, including the edge cases near whatever boundary the fix now guards.
- The vulnerability is genuinely closed. The flaw is gone, not just hidden from the detector that flagged it.
- No new vulnerability is introduced. Trading a SQL injection for a cross-site scripting bug, or a path traversal for a denial-of-service regex, clears the original finding while leaving the program no safer.
Measuring how well a given strategy meets those conditions is the hard part. Work on LLM-driven AVR tends to fall into four families:
- Prompt engineering: shaping the prompt and the context fed to the model, including few-shot examples, to steer it toward a fix that is both functional and secure.
- Agentic methods: splitting the work across LLMs with distinct roles, such as patching, coordinating and reviewing.
- Fine-tuning: training a model on historical vulnerability patches so it gets better at producing security fixes.
- Search-based methods: combining LLMs with classical search-based repair to converge on a patch.
Most real systems blend these. What all of them share is a dependence on data. You cannot improve, or even fairly compare, any of these approaches without a high-quality benchmark, and that is exactly what the industry does not have.
The benchmarking gap
A benchmark that can fairly evaluate AVR has to satisfy three properties at once.
- Realistic: drawn from real production software, with the surrounding repository and multi-file dependencies a real fix has to account for, rather than a single function lifted out of context.
- Diverse: spanning the languages and weakness classes (CWEs) that real systems actually run into.
- Verified exploit: a runnable artefact that triggers the vulnerability, so you can prove it was real before the fix and confirm it is closed after.
The widely used vulnerability datasets each capture one or two of these. None covers all three.
- Devign: a function-level dataset hand-labelled from four large C projects, including FFmpeg and QEMU, prized for its manually curated labels. But it is narrow, C only and a handful of projects, and it ships nothing beyond isolated functions: no build files, runtime, or proofs of exploit.
- LAVA-M: four GNU coreutils programs with bugs automatically injected by LAVA, each shipping a trigger input that provably fires it, so it is exploit-verified by construction. But the bugs are synthetic and unrealistic, magic-value comparisons grafted onto tainted data, and confined to a few small utilities, so it is neither diverse nor representative of real vulnerabilities.
- ARVO: derived from OSS-Fuzz, it builds a containerised environment with a build script and a proof of exploit for each case. Strong on verifiability, but restricted to C/C++ memory-safety bugs.
- DiverseVul: mined from security trackers such as Snyk and Bugzilla across 797 C/C++ projects into a function-level dataset that is broad across CWEs. It ships no build files, runtime, or exploits.
- CVEfixes: broad and multi-language, but assembled from commit histories with no verified proof of the vulnerability, so you are trusting the labels.
- ReposVul: repository-level and realistic, keeping full project context and the dependency graph instead of isolated functions. It provides no exploits or runtime, and its labels are heuristic rather than verified.
- CVE-Genie: an LLM pipeline that reproduces real CVEs end to end, each with a capture-the-flag-style exploit across many languages. Diverse and exploit-backed, though, like any automated pipeline, its output is only as reliable as the models that build it.
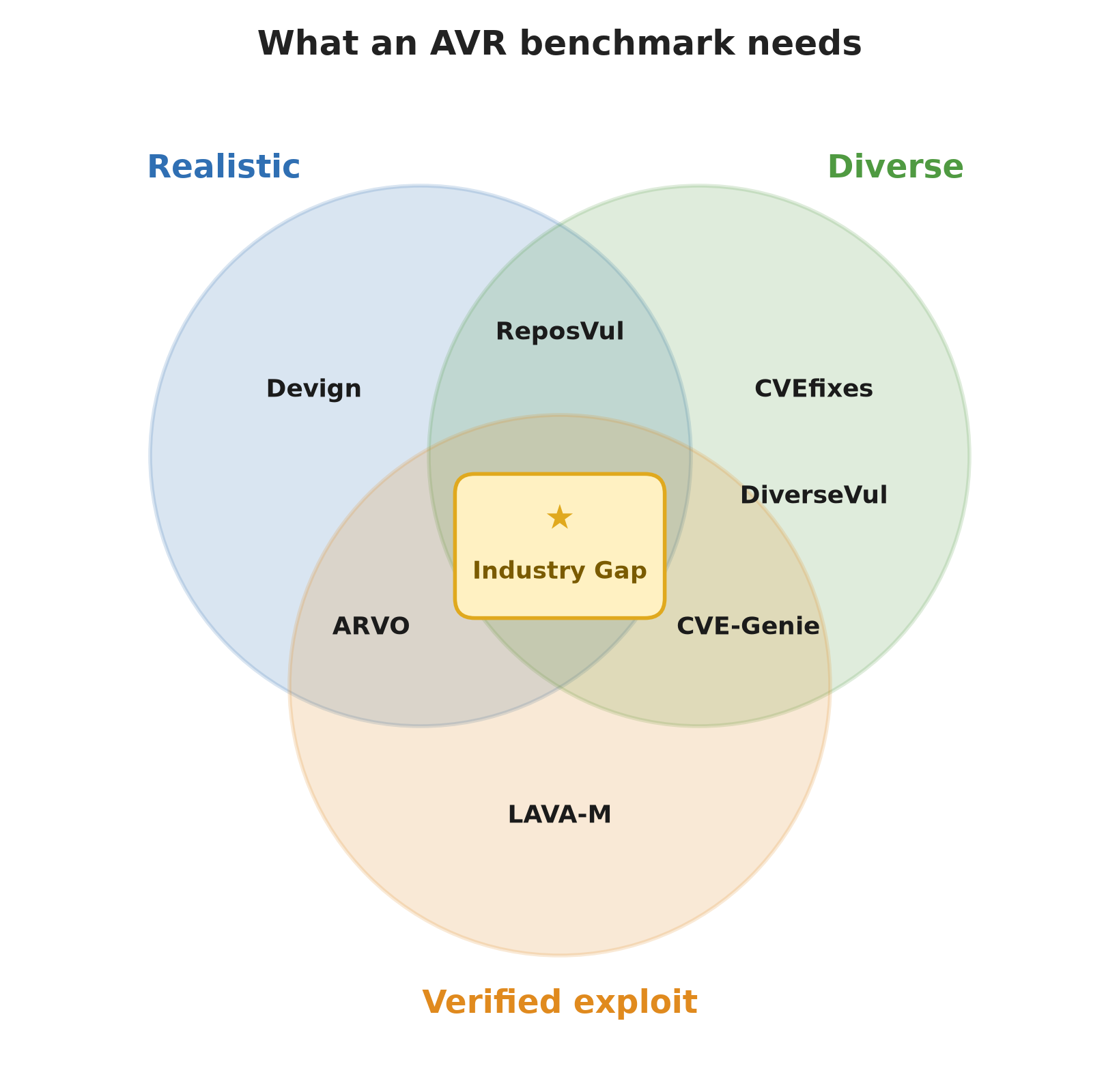
Pick any two of realistic, diverse and verified, and you can find a dataset that delivers them. Find one that delivers all three at scale, across languages, on data that resembles what engineers meet in industry, and the shelf is empty. Until that dataset exists, many of these strategies stay constrained in practice, and an honest read on what they can do stays out of reach.
The part benchmarks miss: context
There is a deeper problem, and it survives even in a dataset that gets all three properties right. Most of them hand the model a vulnerable snippet on its own. In production, the hard part of a repair is rarely the offending line. It is the context around that line, and the right fix depends on information the code alone does not carry. A patch that looks correct in isolation is often wrong once you put it back in the system.
Two cases show it clearly.
- Hardening input validation. Without the trust boundary and the data flow into the sink, a model adds a check in the wrong place, repeats validation already done upstream, or guards the wrong property. The finding goes quiet while the vulnerable path stays open.
- Hardening infrastructure-as-code. Tightening a security group, an IAM policy or a bucket ACL is only safe if you know what legitimately relies on it. Without cloud context, meaning what is actually exposed and what talks to what, the fix can sever a service that depended on the old setting. Without business context, meaning whether the resource is production or a sandbox and who consumes it, the model cannot judge how far it can safely go.
The same gap shows up elsewhere.
- Dependency upgrades generate noise or breakage when the agent cannot see whether your code actually calls the vulnerable function (call-graph reachability), or whether that path is exposed at all (deployment reachability).
- Authorisation fixes need the application's intended role model. The code cannot tell you who is supposed to be allowed through.
- Secret-handling fixes need to know how the organisation manages secrets, whether a vault, a parameter store or injected environment variables, or the model invents an approach the surrounding infrastructure does not support.
- Breaking-change tolerance depends on who calls the code. An internal-only consumer and a public API call for very different repairs.
In every one of these, cloud context and business context are inputs to the fix. Leave them out and the model is guessing. A benchmark that strips them away cannot even ask the question that decides whether a real repair is correct. Closing that gap is the work, so the rest of this is how we go about it.
Only repair real risks
A fix is only as valuable as the finding behind it, and most of what a scanner reports is not worth a pull request: dead code, unreachable paths, dependencies that never ship, findings that were never exploitable to begin with. So before autofix touches anything, every finding goes through triage. Triage works out whether the vulnerable code is reachable in production, how exploitable it is, what data flows through it and how much that data matters, and from that it sets a priority. Findings in dead or test-only code, and findings with solid evidence of a false positive, are dropped. Only the genuinely urgent and important ones become candidates for a fix.
For the findings that warrant it, a separate step tries to prove the risk is real. It attempts the exploit against a running target, and when it succeeds it keeps the evidence: the request and response that triggered the vulnerability, and a script that reproduces it. That proof of exploit travels with the finding. It is the same standard we said public datasets lack, applied to our customers' own findings. We would rather demonstrate that a vulnerability fires than trust that a detector was right. Triage and the exploit step together mean autofix spends its effort, and a developer's attention, only on real, reachable, exploitable risk.
Give the agent the full picture
A repair depends on context, and that context has to come from somewhere. We run a service whose whole job is to understand a customer's estate. Agents read the full codebase and map how it is built, what its entry points are, which functions call which, and where data flows through it. A second layer maps where all of that actually runs: the cloud accounts, the containers, load balancers and gateways, the network paths between them, and the route from the public internet to a given service. The two are stitched into one graph, so a line of code can be traced forward to the container it ships in, the load balancer in front of it and out to the internet, and backward from an exposed endpoint to the function behind it.
That gives a fix the two kinds of context the code alone cannot. Cloud context answers where the code runs and who can reach it: whether the vulnerable path is exposed to the internet, through what, behind which controls, and what sits downstream of it. Business context answers what the code is for and how much it matters: production or sandbox, a crown-jewel service or a throwaway tool, regulated data or none, and who depends on it. With both in hand the agent can make the calls a careful engineer makes. Fix the reachable, exposed vulnerability aggressively. Leave an unreachable transitive dependency alone rather than force a breaking upgrade. Harden the IaC without cutting off a service that relied on the old setting. Tighten validation at the real trust boundary instead of three layers too late.
Plan, then fix, then review
Even with the right context, one model asked to read, fix, test and review in a single pass makes the kind of mistake that passes a glance and fails in production. So we split the work across agents that each do one thing. A planner locates the vulnerable code and writes a focused plan for the smallest change that closes it, without editing anything. An editor applies that plan as precise edits. A separate reviewer, a different model with a fresh view, judges the result against the things that matter: does it fix the root cause rather than a symptom, could the vulnerability still fire, does it preserve existing behaviour, is it minimal and complete. If the reviewer rejects the change, its feedback goes back to the editor and the loop runs again, up to a bounded number of attempts. Where the scanner can re-check the file, we re-run it as a deterministic gate on top of the review: if the original finding still fires, the fix is not done, whatever the model believes. Keeping each agent narrow and putting an independent reviewer between the fix and the pull request is how we hold the error rate down.
Prove it in a sandbox, then keep iterating
A fix that has only been read is not a fix you can trust. So the loop runs inside an isolated sandbox, a throwaway environment that holds the code and nothing else of value, where the agent can safely run commands. There it does what a developer would. It writes a unit test that exercises the vulnerability, a malicious input that should now be blocked and a legitimate one that should still work, and it runs it. It builds the project. For dependency fixes it regenerates the lockfile with the real package manager rather than guessing at cryptographic hashes it has no way to compute. It re-runs the scanner. Only once a fix survives all of that does it become a pull request. The sandbox holds nothing privileged, so even though it runs code derived from a customer's repository, a hostile dependency or a malicious input has nowhere to go and nothing to take. A separate, credentialed step that never runs that code opens the pull request.
Opening the pull request is not the end of the loop. Once it is up, the agent keeps working. When the customer's own CI runs and something fails, it reads the actual failing logs, decides whether the failure is its own doing or pre-existing, and pushes a corrective commit, within a commit budget so it never spirals. When a developer leaves a review comment, it responds: it makes the change that was asked for and replies on the thread, in the plain tone of a colleague rather than a bot. If the branch falls behind the target, it rebases and resolves the conflicts while keeping the fix intact. The pull request opens as a draft and is promoted to ready only once CI is green, with the right reviewers already on it, drawn from the code owners, the team that owns the files, and the people who last worked on them. The description is written to match what triage found: direct and urgent when the risk is proven and reachable, calm and explicit about uncertainty when it is not, never claiming more confidence than the evidence supports, with the proof of exploit and a link to the full context attached.
How we know it works
All of this is a set of bets about what makes a repair trustworthy. We check those bets two ways.
In research, we run against the benchmark described earlier, the one our flywheel keeps building from real production vulnerabilities. Because every case is synthetic, planted in a non-customer codebase, we control the ground truth, and we score a fix on three conditions together: it applied, the vulnerability is gone, and no new finding took its place. On top of that we run a causal exploit check. Each case ships a working exploit and a functional test suite, and the exploit is wired so that it only succeeds because of the planted flaw. Revert the planted vulnerability and the exploit stops working, which means a captured exploit is proof the fix failed and not an artefact of the test. A fix passes only if the exploit no longer fires and the feature's own tests still pass. That catches the two failures that matter most, a fix that quietly breaks the feature and a fix that silences the scanner without closing the hole, on a corpus that grows continuously across languages, weakness classes, cloud postures and business situations.
Research tells us whether a fix is correct. Production tells us whether it is mergeable, which is a higher bar. The number we hold ourselves to is the merge-ready rate: the share of autofix pull requests a team merges with no further edits and no back-and-forth. A pull request earns that only when several things are true at once. The customer's CI passes on the fix. The right reviewer is on it. The description is convincing because it carries the full context from triage, the severity, the exploitability, the reachability and the proof of exploit, with its confidence stated honestly. The team is not buried, because triage and the exploit step kept the volume down to real risks and caps keep any single batch sane. And the evidence that the vulnerability was real is right there in the pull request. A fix that merges untouched is the strongest signal we get that all of that held, and it is the number a research improvement has to move before we trust it: a change ships only when better benchmark scores show up as fixes that real developers merge, at a cost and a speed that make sense.
LLM-driven repair is improving quickly, and the strategies above have all produced real results. What lags behind is our ability to trust and compare them, because the ground we measure on is uneven and blind to context. We have tried to fix the ground: repair only real, proven risks, give the agent the full cloud and business context, split the work across focused agents, prove every fix in a sandbox before it ships and keep iterating after, and judge the whole thing by whether developers merge the result untouched. Until the field has data that is realistic, diverse, exploit-backed, paired with functional tests and set in real cloud and business context, “the scanner stopped complaining” will stay a much weaker claim than it sounds. That is the standard we hold our own autofix to, and the one we think the field should adopt.
Written by: Omri Ram and Tim Thacker
